Fala pessoal, tudo bom?
Semana passada abordamos o tema de intervalos e descobrimos que o QlikView possui uma função própria para se tratar desses casos. Não viu? Clique aqui!
Definições do IntervalMatch
Também quero aproveitar para relembrar algumas definições do IntervalMatch:
- Antes do comando intervalmatch, o campo que contém os pontos de dados discretos (“Nota” no exemplo do post anterior) já deve ter sido lido no QlikView. O próprio comando intervalmatch não lê esse campo a partir da tabela da base de dados.
- A tabela lida no comando intervalmatch deve sempre conter exatamente dois campos (“Min” e “Max” no exemplo do post anterior). Para estabelecer um link com outros campos, é necessário ler os campos de intervalo com campos adicionais em um comando load ou select separado.
- Os intervalos estão sempre fechados, isto é, sempre contêm pontos de extremidade.
- Os limites não numéricos fazem com que o intervalo seja desconsiderado (indefinido)
- Os limites nulos (NULL) estendem o intervalo indefinidamente (ilimitado).
- Os intervalos podem estar sobrepostos, ou seja, posso ter dois intervalos que contenham valores repetidos, esses valores estarão vinculados a todos os intervalos correspondentes.
Caso a utilizar IntervalMatch Estendido
Essa semana iremos tratar de um intervalo que não depende simplesmente do intervalo de valores, mas também depende de um segundo campo que define a qual intervalo estamos tratando. Podemos chamar esse segundo intervalo de campo chave.
Resgatando o exemplo da semana passada em que tínhamos uma tabela com a classificação das notas e outra com as notas recebidas por cada aluno, vamos adicionar uma nova coluna com o nome da escola. Imagine que o nosso professor ministre aulas em duas escolas diferentes e cada uma dessas escolas possuem a sua própria classificação das notas.
Na escola Puríssimo a classificação é:
- de 0 até 34 é Nota “E”
- de 35 até 40 é Nota “D”
- de 41 até 60 é Nota “C”
- de 61 até 80 é Nota “B”
- de 81 até 100 é Nota “A”
Na escola Sesi a classificação é:
- de 0 até 15 é Nota “E”
- de 16 até 40 é Nota “D”
- de 41 até 60 é Nota “C”
- de 61 até 70 é Nota “B”
- de 71 até 100 é Nota “A”
Como temos classificações diferentes em duas escolas (CHAVE) diferente, então a nossa tabela de notas deve possuir a qual escola (CHAVE) aquela nota (do aluno) pertence.
Prática
Em primeiro lugar crie a nossa tabela com os intervalos.
Grade:
LOAD * INLINE [
Escola, Min, Max, Grade
Escola Puríssimo, 0, 34, E
Escola Puríssimo, 35, 40, D
Escola Puríssimo, 41, 60, C
Escola Puríssimo, 61, 80, B
Escola Puríssimo, 81, 100, A
Escola Sesi, 0, 15, E
Escola Sesi, 16, 40, D
Escola Sesi, 41, 60, C
Escola Sesi, 61, 70, B
Escola Sesi, 71, 100, A
];
Agora vamos criar a nossa tabela das notas por escola e aluno.
Notas:
LOAD * INLINE [
Escola, Nota, Aluno
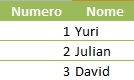
Escola Puríssimo, 30, Yuri
Escola Puríssimo, 50, Edson
Escola Puríssimo, 99, Alan
Escola Puríssimo, 10, Geraldo
Escola Puríssimo, 93, Henrique
Escola Sesi, 27, Christian
Escola Sesi, 44, Michele
Escola Sesi, 80, Roberto
Escola Sesi, 76, Ivanir
Escola Sesi, 98, Zé
];
Note: A coluna “Escola” é a chave que define a nota e a classificação, sem ela não saberíamos informar a classificação da nota desse aluno, pois agora temos dois intervalos diferentes na mesma tabela.
Agora vamos para a utilização do IntervalMatch Estendido
A utilização do IntervalMatch Estendido deve-se partir da leitura da tabela de intervalos e o comando IntervalMatch deve-se relacionar com a coluna que deve ser checada dentro do intervalo e a coluna de chave:
Usando_IntervalMatch_Estendido:
IntervalMatch(Nota,Escola) //Comando IntervalMatch chamando a coluna a ser checada dentro do Intervalo e a chave para definir a qual intervalo o valor se refere.
Usando_IntervalMatch_Estendido:
IntervalMatch(Nota,Escola) //Comando IntervalMatch chamando a coluna a ser checada dentro do Intervalo e a coluna de //chave das classificações
LOAD
Min, //Primeiro o menor valor do intervalo
Max, //depois o maior valor do intervalo
Escola //Por último a coluna chave.
RESIDENT Grade; //Tabela de Intervalos
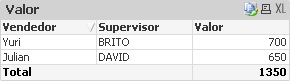
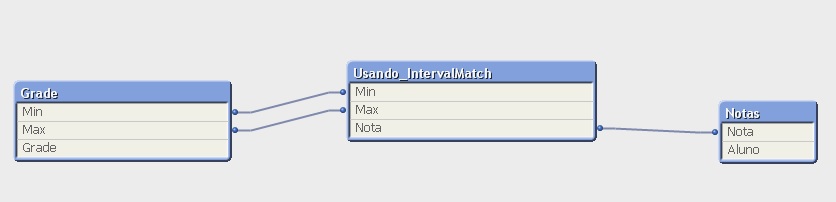
Com o resultado agora teremos a tabela “Usando_IntervalMatch_Estendido” que possui as colunas: Min, Max, Nota e Escola. Essa tabela já fez a ligação entre as tabelas Nota e Grade, veja:

Agora é só fazer o JOIN necessário para remover essa chave sintética. Remova a parte do IntervalMatch e faça a alteração abaixo:
LEFT JOIN (Notas)
IntervalMatch(Nota,Escola) //Comando IntervalMatch chamando a coluna a ser checada dentro do Intervalo e a coluna de chave das classificações
LOAD
Min, //Primeiro o menor valor do intervalo
Max, //depois o maior valor do intervalo
Escola //Por último a coluna chave.
RESIDENT Grade; //Tabela de Intervalos
LEFT JOIN (Notas)
LOAD
*
RESIDENT Grade;
DROP TABLE Grade;
DROP Fields Min, Max;
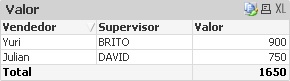
Resultado final

Download da aplicação de exemplo!
Conclusão
Esse é um caso que mais ocorre em nosso dia a dia em relação ao caso do post anterior, pois dificilmente teremos apenas um intervalo de dados para checar.
E reforço o texto utilizado no post anterior: É uma boa prática conhecermos muitas das funções que o QlikView nos oferece, pois estas funções sempre irão nos poupar linhas e linhas de código.
Até a próxima semana pessoal!