Fala pessoal! Tudo bom?
Em algum momento já se depararam com a possibilidade de cálculo do tempo de atendimento (SLA)? Considerando apenas o tempo útil da empresa?
Parece simples, mas não é!
Esse cálculo envolve muitas condicionais e tratativas. Confesso que a primeira vez que fui desenvolver, fiquei um bom tempo (MUIIITO TEMPO) pensando em todas as possibilidades do cálculo!
Vou citar algumas:
1 – Abre dentro do horário e fecha no mesmo dia dentro do horário
2 – Abre dentro do horário e fecha no mesmo dia fora do horário
3 – Abre fora do horário e fecha no mesmo dia dentro do horário
4 – Abre fora do horário e fecha no mesmo dia fora do horário
5 – Abre dentro do horário e fecha em outro dia dentro do horário
6 – Abre dentro do horário e fecha em outro dia fora do horário
7 – Abre fora do horário e fecha em outro dia dentro do horário
8 – Abre fora do horário e fecha em outro dia fora do horário
9 – Abre dentro do horário e fecha em outro dia dentro do horário
10 – Abre dentro do horário e fecha em outro dia fora do horário
11 – Abre fora do horário e fecha em outro dia dentro do horário
12 – Abre fora do horário e fecha em outro dia fora do horário
13 – Abre antes do final de semana dentro do horário e fecha no final de semana
14 – Abre antes do final de semana dentro do horário e fecha no próximo dia útil dentro do horário
15 – Abre antes do final de semana fora do horário e fecha no final de semana
16 – Abre antes do final de semana fora do horário e fecha no próximo dia útil fora do horário
17 – Abre antes do feriado dentro do horário e fecha no feriado
18 – Abre antes do feriado dentro do horário e no próximo dia útil após o feriado antes do horário
19 – Abre antes do feriado dentro do horário e no próximo dia útil após o feriado dentro do horário
20 – Abre antes do feriado fora do horário e no próximo dia útil após o feriado dentro do horário
E acredite, existem mais condicionais.
Vamos ao que interessa, a prática!
Funções
Para este exemplo, utilizaremos as seguintes funções:
- FRAC
- FLOOR
- MakeTime
- NetWorkDays
- LastWorkDate
- FABS
- Interval
Manual!! Me ajude…
FRAC
Utilização: frac(x)
Descrição: Retorna a parte fracionária de um número.
Exemplos:
frac( 11,43 ) retorna 0,43
FLOOR
Utilização: floor(x [ , base [ , offset ]])
Descrição: Arredondamento de x para baixo até o múltiplo mais próximo de base com um deslocamento de offset. O
resultado é um número.
Exemplos:
floor( 2,4 ) retorna 2
floor(11,43) retorna 11
MakeTime
Utilização: MakeTime( hh [, mm [, ss [.fff ]]] )
Descrição: Retorna uma hora calculada a partir da hora hh, do minuto mm, do segundo ss com uma fração fff até um
valor em milissegundos.
Se nenhum minuto for indicado, 00 será assumido.
Se nenhum segundo for indicado, 00 será assumido.
Se nenhuma fração de segundo for indicada, 000 será assumido.
Exemplos:
maketime( 22 ) retorna 22:00:00
maketime( 22, 17 ) retorna 22:17:00
maketime( 22, 17, 52 ) retorna 22:17:52
NetWorkDays
Utilização: networkdays (data_inicial, data_final {, feriado})
Descrição: Retorna o número de dias úteis (segunda-sexta) entre e incluindo a data_inicial e a data_final,
levando em conta quaisquer feriados opcionais listados. Todos os parâmetros devem ser datas ou
datas/horas válidas.
Exemplos:
networkdays (‘2007-02-19’, ‘2007-03-01’) retorna 9
networkdays (‘2006-12-18’, ‘2006-12-31’, ‘2006-12-25’, ‘2006-12-26’) retorna 8
LastWorkDate
Utilização: lastworkdate(data_inicial, nº_de_dias_úteis {, feriado})
Descrição: Retorna a data final mais recente para obter o número_de_dias_úteis (segunda-sexta) se o início for
na data_inicial, considerando-se os feriados listados opcionalmente. Data_inicial e feriado devem
ser datas ou datas/horas válidas.
Exemplos:
lastworkdate (‘2007-02-19’, 9) retorna ‘2007-03-01’
lastworkdate (‘2006-12-18’, 8, ‘2006-12-25’, ‘2006-12-26’) retorna ‘2006-12-29’
FABS
Utilização: fabs(x)
Descrição: É o valor absoluto de x. O resultado é um número positivo.
Exemplos:
fabs( 2,4 ) retorna 2,4
fabs( -3.8 ) retorna 3.8
Interval
Utilização: interval( expressão [ , código de formato ])
Descrição: A função interval formata a expressão como um intervalo de tempo, de acordo com o caracter fornecido
como código de formato. Se o código de formato for omitido, será utilizado o formato de hora definido no
sistema operacional. Os intervalos podem ser formatados como hora, dia ou como uma combinação de dias,
horas, minutos, segundos e frações de segundos.
Exemplos:
Os exemplos abaixo supõem as seguintes configurações do sistema operacional:
Formato de data abreviada: YY-MM-DD
Formato de hora: hh:mm:ss
Separador de número decimal: .
interval( A ) em que A=0.375 retorna:
Caracter 09:00:00
Número 0.375
interval( A ) em que A=1.375 retorna:
Caracter 33:00:00
Número 1.375
Vamos ao código
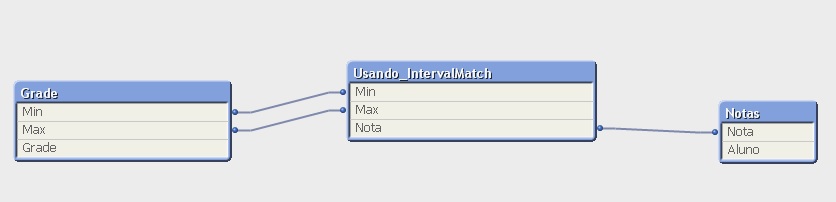
Nosso exemplo vai calcular o tempo útil de SLA de uma empresa que possui como horário de trabalho das 08:00 até as 18:00 de Segunda à Sexta. Nessa empresa a hora do almoço é contabilizada!
Calcularemos o tempo de fechamento de chamados, ou seja, nossa tabela possui uma data de abertura e data de encerramento.
Vamos lá….
Em primeiro lugar crio uma variável chamada Feriado e cadastro os possíveis feriados, mas lembre-se de cadastrar esses feriados com os valores entre apóstrofes e delimitados por virgula “,”.
Segue exemplo:
SET Feriados = ’09/06/2015′,’10/06/2015′;
Em segundo, devo tratar a data de abertura e data de encerramento.
Para a coluna de data de abertura:
- Se a abertura é antes das 08 horas, então passa a ser as 08 horas do mesmo dia
- Se a abertura é após as 18 horas, então passa a ser as 08 horas do próximo dia útil (considerando feriados e finais de semana).
Para a coluna de data de encerramento:
- Se o encerramento é antes das 08 horas, então passa a ser 18 horas do dia útil anterior
- Se o encerramento é depois das 18 horas, então passa a ser 18 horas do mesmo dia
Em terceiro, faço os cálculos finais, com as condições:
- Se a data de encerramento é igual ao dia de abertura, então faço uma coluna menos a outra e assim temos o tempo útil
- Se a data de encerramento é diferente ao dia de abertura, então faço preciso fazer o seguinte cálculo:
- A – uma coluna menos a outra para contabilizar a quantidade de horas no intervalo
- B – Verifico a quantidade de dias que existe dentro desse intervalo e multiplico por 14 (14 horas não úteis dentro de um dia de 10 horas úteis). Lembre-se que das 08:00 até as 18:00 temos 10 horas, logo se o dia possui 24 horas, então neste dia temos 14 horas não úteis.
- C – Verifico a quantidade de dias não uteis dentro do intervalo e multiplico por 24 (Esses dias não úteis são os Sáb, Dom e Feriados)
- A conta final fica: A – B – C
Ufa!!
Bem chatinho né? Isso porque não estamos desconsiderando a hora de almoço!! Mas isso fica para um próximo post!
Desta vez não irei colar o código, mas peço que façam o download da aplicação de exemplo. Opa, Só clicar aqui para fazer o download!
Espero que gostem!
Até a próxima semana!