Fala pessoal, tudo bom?
Mais um post sobre os CUIDADOS que devemos ter em nosso script para evitar erros!
Dessa vez quero falar sobre a leitura de múltiplos arquivos através dos caracteres curinga* (ahn? ajuda aí!)
Wikipedia diz: Em computação os caracteres-curinga são utilizados em casamento de padrões para substituir algum outro carácter desconhecido em uma sequência de caracteres.
É muito utilizado ao realizar um glob para procurar arquivos cujo nome ou caminho completo são desconhecidos. Nos interpretadores de comandos, o caractere asterisco (*) é reconhecido como um caractere-curinga que casa com qualquer número de caracteres desconhecidos e o caractere interrogação (?) é um curinga que casa com um único caractere desconhecido.
(entendido? rsrs! retornando ao texto) quando utilizamos em conjunto de união de tabelas (JOIN! – Neste exemplo o CONCATENATE não é um erro, mas falo disso no final).
É um erro bobo, mas fácil de ser cometido. Sabe por quê? Porque conhecemos os conceitos e comportamentos do QlikView.
Conceitos e comportamentos
Sabemos que o QlikView possui o comportamento de unir (transformar em apenas uma) tabelas que possuem os mesmos campos (com a mesma nomenclatura), por esta razão quando utilizamos o caractere curinga para fazer uma leitura múltipla de arquivo, o QlikView “faz o favor” de unir todas essas tabelas (desde que respeite a regra anterior que falamos) em apenas uma.
Exemplo
Imagine um cenário com em que precisamos carregar planilhas com notas fiscais. Cada uma das planilhas possui informação de apenas um mês/ano.
Lista de arquivos: NF_jan12.xls, NF_fev12.xls, NF_mar12.xls e NF_abr12.xls.
Esses arquivos estão perfeitos para serem carregados de uma única vez através do caractere curinga “*”.
Ah, vale lembrar que esses arquivos estão todos do mesmo padrão, isso inclui: nome das colunas e nome da aba a serem carregadas.
Em nosso script do qlikview:

Resultado:
A leitura dos quatros arquivos se resumiram em apenas uma tabela devido ao comportamento do QlikView.
Agora vamos para o exemplo em que podemos se esquecer desse comportamento e cometer um erro grave.
O problema
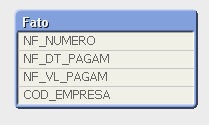
Agora temos uma tabela principal com o nome das empresas de um grupo, conforme imagem:

Queremos exibir os dados de faturamento, mas mostrando todas as empresas, ou seja, mesmo que a empresa não tenha faturado nada, esta deve exibir no relatório.
Tecnicamente, iremos carregar primeira a tabela com a descrição das empresas e depois fazer o LEFT JOIN utilizando a tabela de nota fiscal. Nosso script seria:

Executando o script, veja o resultado:
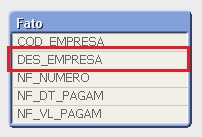

O resultado ficou como esperado! As empresas 4 e 5 estão sendo exibidas sem nenhuma nota fiscal e o restante das informações fez a ligação com a descrição da empresa.
Opa, mas peraí! Carreguei informações de Jan/2013, Fev/2013, Mar/2013 e Abr/2013… Por quê esta aparecendo somente os dados de Abr/2013?
O erro cometido
Aparentemente fizemos tudo certo, mas um grande detalhe de comportamento nos atrapalhou: leitura múltipla de arquivos em conjunto com união de tabelas.
Vamos pensar…
Seguindo o comportamento de execução do Qlikview, em primeiro lugar carregamos a tabela Empresas e passamos a chama-la de Fato, tendo essa tabela carregada (em memória), realizamos a leitura múltipla das tabelas de notas fiscais e fazemos a união desta tabela com a data Fato através da coluna COD_EMPRESA.
Durante a execução, após ter a tabela fato em memória, da leitura múltipla, o QlikView, faz a leitura do primeiro arquivo encontrado que é “NF_abr13.xls” (Por quê esse? Ordem Alfabética!) e realiza o LEFT JOIN com a tabela fato, depois disso o QlikView faz a leitura do próximo arquivo “NF_fev12.xls” e realiza o LEFT JOIN com a tabela fato. OPA !!!! neste momento a tabela Fato já possui as colunas do arquivo de Empresas: COD_EMPRESA e DES_EMPRESA, e as colunas do arquivo de Nota Fiscal: NF_NUMERO, NF_DT_PAGAM, NF_VL_PAGAM e COD_EMPRESA, ou seja, ao tentar fazer o LEFT JOIN do segundo arquivo “NF_fev12.xls”, o QlikView não vai encontrar (match) a combinação de registros das colunas (NF_NUMERO, NF_DT_PAGAM, NF_VL_PAGAM e COD_EMPRESA).
Não entendi!
No primeiro arquivo, a chave de ligação do LEFT JOIN é apenas a coluna COD_EMPRESA (essa é a chave correta), porém a partir do segundo arquivo, a chave de ligação passa a ser: COD_EMPESA, NF_NUMERO, NF_DT_PAGAM, e NF_VL_PAGAM porque essas colunas já foram carregadas no primeiro arquivo carregado.
Logicamente, essa nova chave não fará mais nenhuma ligação por não termos essa combinação de registros.
Desenhando (esse momento foi muito difícil pra mim rsrs!!!)


O que fazer?
Bom, se o comportamento do QlikView é esse, então nestes casos é sempre importante termos um passo antes para carregar todos esses arquivos e guardar em uma tabela temporária, para depois fazer o JOIN. Dessa forma:

E o concatenate?
Para concatenate não tem problema, pois o processo é de forçar a concatenação, independente de quais colunas estejam nas tabelas.
Conclusão
É muito importante conhecermos a fundo os conceitos e comportamentos do QlikView. Neste caso, nossa cabeça pensa que o QlikView vai carregar todos os arquivos (concatenando-os) para depois fazer o JOIN, porém aprendemos que o QlikView não se comporta dessa forma.
Para quem deseja, segue a aplicação de exemplo para download.
Até a próxima semana pessoal!