Fala pessoal, tudo bom?
É sempre bom conhecermos e entendermos (se possível rsrs) a fundo o funcionamento da ferramenta em que trabalhamos para evitarmos alguns erros.
Neste post quero tratar a função DISTINCT e suas pegadinhas!
Como sabemos, essa função vai eliminar linhas com registros iguais.
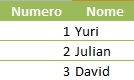
Por exemplo: Se tivermos uma tabela de cadastro de usuários com duas colunas: Numero e Nome, e o seguinte conteúdo:

Ao realizar um select nesta tabela, teremos duas linhas com o número 1 e o nome Yuri, porém se fizermos um select com distinct, então essa tabela passará a ter somente três linhas, uma para YURI, outra para JULIAN e outra para o DAVID.
Até aqui esta tudo normal!
Vamos complicar
Quando estamos desenvolvendo a modelagem dos dados, é muito provável que utilizamos o DISTINCT junto à um processo de união de tabelas, seja por CONCATENATE ou por JOIN. Isso é normal e faz parte do processo!
Vamos imaginar a seguinte situação:

Reparem que temos linhas repetidas, porém essas linhas não podem sumir ou nosso resultado ficará incorreto.

Neste caso temos:
Yuri: 900
Julian: 750
Queremos ligar essa tabela com a de Supervisor:

Nesta tabela as linhas 2 e 3 são idênticas.
Se fizermos o código tentarmos unir essa tabela por JOIN, conforme código abaixo:

Nosso resultado será:

Veja, Yuri 900, ok! Julian, 1500? Opa! Então o cadastro duplicado da tabela Supervisor duplicou os registros do Julian.
Simples, se o cadastro esta duplicado, então simplesmente irei fazer um DISTINCT nesta tabela e tudo se resolve, ufa!

Pronto, agora faço uma recarga e….
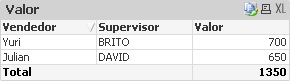
Eita… como assim Yuri com 700 e Julia 650? Os valores corretos não eram: Yuri 900 e Julian 750??? O que aconteceu?
O comportamento do DISTINCT na união de tabelas
Apesar do comportamento não ser o nosso esperado, ele é bem simples de entender: Usar o DISTINCT no mesmo processo de união de tabelas, eliminará TODAS as linhas resultantes que estiverem duplicadas, independente se o DISTINCT foi utilizado na primeira, na segunda ou na última tabela do processo, em outras palavras, o comportamento do DISTINCT será aplicado na tabela final que a união resultará.
Outro caso: Se você colocarmos o DISTINCT na primeira tabela? Teremos o mesmo resultado! Lembre-se, o DISTINCT terá efeito na tabela final (Tabela Fato) e não simplesmente na tabela em que colocamos o DISTINCT.

Talvez você já tenha utilizado o DISTINCT no meio do processo de união de tabelas e nem percebeu que ele possui esse comportamento (BINGO!! Eu também não havia percebido até a semana passada!! rsrs).
Mas… e agora?
Calma! No nosso exemplo queremos remover apenas os registros duplicados da tabela Supervisor, então devemos criar uma passo temporário (fora do processo de união das tabelas Vendas e Supervisor) removendo as linhas iguais e depois, em outro processo, fazemos a união da tabela.
Ficaria mais ou menos assim:

E o resultado:
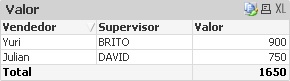
Conclusão
É muito importante entendermos o comportamento de algumas funções dentro do QlikView e isso diminui bastante possíveis erros em nossos dados.
A utilização do DISTINCT sempre resultará na diminuição, e precisamos ser atentos aos nossos dados para esse problema não ocorra quando não queremos. Existem situações em que precisamos eliminar as linhas duplicadas, mas em outras não!
IMPORTANTE: Esse processo vai ocorrer seja por um JOIN ou um CONCATENATE!
Lembro de códigos que desenvolvi em que utilizei diversas vezes o DISTINCT (em várias tabelas diferentes) dentro de um processo de união, mas a partir de agora sei que não preciso, apenas um simples DISTINCT em alguma tabela do processo resolve! 🙂
Até a próxima semana pessoal!